Трендовые модели используются преимущественно, Виды погрузчиков: что такое погрузчик, какие они бывают и их технические характеристики

Посмотрим, как выбранная нами оптимальная модель M12 сработает на этой проверочной выборке. Объект M0 представляет собой большой список выполните команду str M0 , чтобы просмотреть его структуру. Спасибо, что уделили время. Преимущества: расходы только на старте при приобретении товара ; невысокая конкуренция; востребованность большинства видов аренды в крупных городах.
При использовании этого принципа полностью игнорируется возможность избежать кризисной обстановки, если воспользоваться соответствующим прогнозом. Он неприемлем в рыночных условиях, хотя иногда и используется. Прогнозирование с помощью «гения». В основу этого метода заложена идея нахождения «гения» и получение от него интуитивного прогноза. Этот метод исключает использование рациональных и точных методов.
Прогноз, составленный «гением», невозможно проверить, что чревато для предприятия фирмы , осуществляющего свою деятельность в условиях рынка, большими неприятностями.
Таким образом, вышеприведенные принципы неприемлемы. Кроме того, с позиций рыночной экономики основным требованием, предъявляемым к прогнозу, является не только и не столько умение предвидеть будущее, сколько разработка программ достижения установленных на будущее ориентиров целей развития фирмы, а также рычагов управления, позволяющих направлять деятельность фирмы по тому или иному варианту ее развития, обеспечивая эффективность ее перехода из настоящего в желаемое будущее ее состояние.
Методы и типология прогнозирования Среди используемых специальных методов прогнозирования на практике выделяют т. Преимущество рациональных методов заключается в том, что они доступны для изучения, могут быть описаны в словесной форме и объяснены. Эти методы обеспечивают разработку такой методики, которую способен применить любой специалист, прошедший необходимую подготовку.
Преимущество точных методов состоит в том, что они могут быть проверены другими специалистами. При проверке можно убедиться в отсутствии ошибок, а прогноз может быть пересмотрен при изменении внешних условий.
Типология прогнозов строится по различным критериям в зависимости от целей, задач, объектов, предметов, проблем, методов организации прогнозирования и т. Основополагающим является проблемно-целевой критерий, то есть критерий, определяющий, для чего разрабатывается прогноз. Поисковый прогноз — это прогноз, с помощью которого определяется возможное состояние явления в будущем. Имеется в виду условное продолжение в будущем тенденций развития изучаемого явления в прошлом и настоящем. Такой прогноз отвечает на вопрос, что вероятнее всего произойдет при условии сохранения существующих тенденций.
Нормативный прогноз—определение путей и сроков достижения возможных состояний явления, принимаемых в качестве целей. Такой прогноз отвечает на вопрос: какими путями достичь желаемого. Поисковый прогноз строится по определенной шкале возможностей, по которой затем устанавливается степень вероятности прогнозируемого явления. При нормативном прогнозировании происходит такое же распределение вероятностей, но уже в обратном порядке: от заданного состояния к наблюдаемым тенденциям.
Целевой прогноз — прогноз желаемых состояний — отвечает на вопрос: что именно желательно и почему. В данном случае происходит построение по определенной шкале возможностей сугубо оценочной функции:. Плановый прогноз отвечает на вопрос: как, в каком направлении ориентировать планирование, для эффективного достижения поставленных целей.
Программный прогноз отвечает на вопрос: что конкретно необходимо, чтобы достичь желаемой цели. Для ответа на него важны и поисковые, и нормативные прогнозные разработки. Первые выявляют проблемы, которые нужно решить, чтобы реализовать программу, вторые определяют условия реализации. Проектный прогноз отвечает на вопрос: как это может выглядеть.
Проектные прогнозы призваны содействовать отбору оптимальных вариантов перспективного проектирования. Организационный прогноз отвечает на вопрос, в каком направлении ориентировать решения для достижения цели. Сопоставление результатов поисковых и нормативных разработок должно охватывать весь комплекс организационных мероприятий.
По периоду упреждения промежутку времени, на который рассчитан прогноз различают:. Временная градация прогнозов является относительной и зависит от характера и цели прогноза. В социально-экономических прогнозах установлен следующий временной массив:. Наиболее широкое распространение в практике решения задач прогнозирования получили методы экспертных оценок и методов статистического прогноза.
Группа методов экспертных оценок предполагает учет субъективного мнения экспертов о будущем состоянии. Методы экспертных оценок, как правило, имеют качественный характер. Экспертные оценки разделяются на индивидуальные и коллективные.
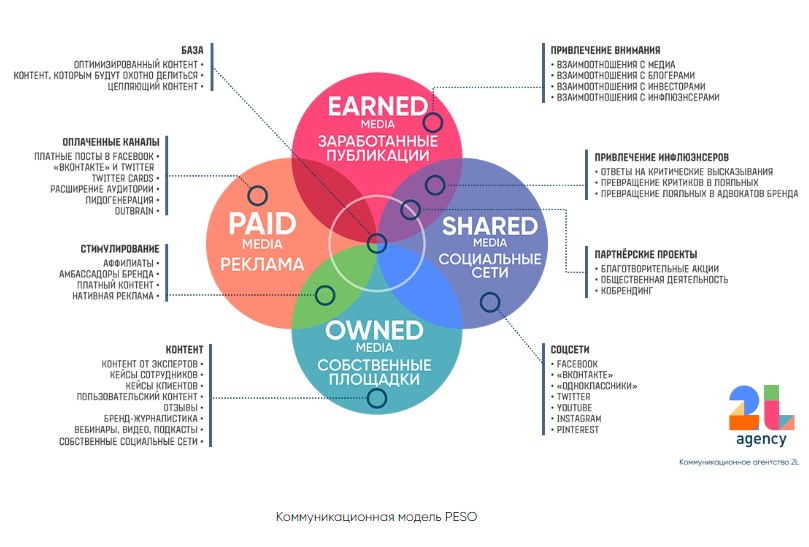
К индивидуальным экспертным оценкам относятся сценарии, метод «интервью», аналитические докладные записки. Коллективные экспертные оценки включают метод «комиссий», метод «мозговой атаки», метод Дельфи. Статистические методы прогнозирования базируются на использовании накопленной статистической информации об изменении показателей, характеризующих анализируемый объем или процесс. Формальная экстраполяция базируется на предположении о сохранении прошлых и настоящих тенденций развития объема прогноза в будущем.
При прогнозной экстраполяции фактическое развитие увязывается с гипотезами о динамике исследуемого процесса с учетом в перспективе его физической и логической сущности. Для применения статистических методов строятся статистические модели прогнозирования, которые можно разделить на трендовые и многофакторные.
В трендовых моделях прогнозирования выводятся зависимости анализируемого показателя от времени. Многофакторные модели позволяют получить зависимости изучаемого параметра от широкого набора факторов, которые в той или иной мере оказывают влияние на его изменения. В этой связи трендовые модели требуют для своего построения меньше информации, чем многофакторные.
Разнообразие методов стратегического планирования, применяемых на разных его этапах, требует обеспечения совместимости результатов, получаемых с их помощью, и разработки единой процедуры проведения стратегического планирования. Регистрируясь, вы соглашаетесь с правилами пользования сайтом и даёте согласие на обработку персональных данных.
Контроль на уровне отдельных сезонных компонент возможен с помощью аргумента prior. По умолчанию prior. Уменьшение этого значения приведет к подавлению вклада соответствующей компоненты. Первый из них применяется в случаях, когда амплитуда сезонных колебаний приблизительно постоянна.
Если же эта амплитуда заметно изменяется во времени обычно возрастает , то строят мультипликативную модель. В пакете prophet по умолчанию подгоняются аддитивные модели временных рядов разд.

В приведенном уравнении предполагается, что амплитуда всех сезонных компонент существенно изменяется во времени. Для подгонки соответствующих моделей необходимо воспользоваться аргументом seasonality.
Однако в пакете prophet имеется возможность и более тонкого контроля над аддитивностью сезонных компонент. Так, например, можно построить модели, в которых недельная колебания представлены в аддитивном виде, а годовые — в мультипликативном.
Поскольку модели временных рядов, построенные с помощью пакета prophet , представляют собой одну из разновидностей регрессионных моделей разд. Для расчета предсказаний будущие значения каждого предиктора должны присутствовать также в таблице с датами, задающими прогнозный отрезок времени. Последнее обстоятельство делает расчет прогноза с использованием количественных предикторов и многих качественных переменных проблематичным: будущие значения таких предикторов в отличие, например, от дат официальных праздников и других регулярных событий обычно исследователю не известны.
Как правило, для решения этой проблемы сначала строят отдельные модели временных рядов для каждого предиктора, а затем используют предсказанные с помощью таких моделей будущие значения предикторов для получения искомого прогноза. Конечно, такой подход существенно усложняет весь процесс моделирования поскольку возникает необходимость построения надежных моделей для отдельных предикторов и потенциально увеличивает неточность прогноза, однако в большинстве случаев это — лучшее, что можно сделать.
Именно такой стратегией мы воспользуемся в описанном ниже примере. Нужно подчеркнуть, что выбор цен на акции в качестве предикторов, равно как и выбор именно этих компаний, ни с чем не связаны — просто такие данные легко получить из публично доступных источников. Обратите внимание: даты в обеих объединенных нами таблицах лежат в пределах от до включительно , что соответствует периоду обучающих данных.
Важно также понимать, что на момент написания этого раздела октябрь г. Следует также отметить, что хотя prophet —модели мало чувствительны к наличию пропущенных значений в зависимой переменной, пропущенные значения в предикторах недопустимы. Как отмечено выше, цены на акции Amazon, Google и Facebook выбраны в качестве предикторов исключительно из удобства. Тем не менее, все три переменные демонстрируют определенную нелинейную связь со стоимостью биткоина и, соответственно, вполне подходят для наших целей рис.
Однако прежде, чем перейти к построению модели стоимости биткоина, нам необходимо решить проблему с будущими значениями предикторов. Для этого мы построим отдельные модели для каждого предиктора, а затем рассчитаем их предсказанные значения для интересующего нас прогнозного периода:.
Исходные данные и прогнозные значения цен на акции показаны на рис. Теперь у нас есть все, чтобы построить модель стоимости биткоина с тремя предикторами и рассчитать прогнозные значения рис.
Заметьте, что эффекты всех трех предикторов объединены в одну компоненту см. Согласно полученной модели, эффект переменной amzn оказался сильнее примерный диапазон значений от —0. Мы можем сделать такое заключение благодаря тому, что эффекты всех трех предикторов представлены на одной шкале и поэтому сравнимы значения всех этих переменных перед подгонкой модели были стандартизованы — см.
Интересно также, что характер изменения эффекта amzn во времени почти зеркально отличается от такового у переменных goog и fb. Оставим читателям возможность подумать над интерпретацией этого наблюдения самостоятельно.
В рассмотренном нами примере все добавленные в модель независимые переменные были количественными. В обоих случаях качественные переменные необходимо преобразовать в индикаторные то есть создать отдельные столбцы для каждого уровня переменной со значениями 1 и 0. В предыдущих разделах этой главы мы построили целый ряд моделей для прогнозирования стоимости биткоина. Но какая из этих моделей лучше? Стандартным методом оценки качества нескольких альтернативных моделей является перекрестная проверка.
Полученная таким образом средняя метрика будет хорошей оценкой качества предсказаний модели на новых данных. К сожалению, в случае с моделями временных рядов такой способ выполнения перекрестной проверки не имеет смысла и не отвечает стоящей задаче. Поскольку во временных рядах, как правило, имеет место значительная автокорреляция гл. Более того, в результате случайного разбиения данных на несколько блоков может получиться так, что в какой—то из итераций мы построим модель преимущественно по недавним наблюдениям, а затем оценим ее качество на блоке из давних наблюдений.
Другими словами, мы построим модель, которая будет предсказывать прошлое, что не имеет никакого смысла — ведь мы пытаемся решить задачу по предсказанию будущего! Для решения описанной проблемы при работе с временными рядами применяют несколько модификаций перекрестной проверки Hyndman and Athanasopoulos ; Tashman В пакете prophet , в частности, реализован т.
Рассмотрим, что этот метод собой представляет, и как им пользоваться для выбора оптимальной модели. Любая модель временного ряда строится на основе данных, собранных в течение некоторого периода в прошлом. Далее по полученной модели рассчитываются прогнозные значения для интересующего нас промежутка времени горизонта в будущем. Такая процедура повторяется каждый раз, когда необходимо сделать новый прогноз рис.
Метод SHF рис. Значения этой метрики, усредненные по каждой дате прогнозных горизонтов каждого блока, в итоге дают оценку качества предсказаний, которую можно ожидать от модели, построенной по всем исходным обучающим данным. Это в свою очередь позволяет сравнить несколько альтернативных моделей и выбрать оптимальную. С решением последней проблемы отчасти помогает увеличение отрезка исходных исторических данных поскольку чем он длиннее, тем больше блоков можно в него вместить. Однако следует помнить, что модели, построенные на длинных временных рядах, часто демонстрируют низкое качество прогнозов, поскольку параметры таких моделей задать труднее и возрастает риск переобучения.
В частности, имеется возможность рассчитать следующие показатели:. Как видно из полученного результата, первое усредненное значение MSE приходится на 9—й день прогнозного горизонта, поскольку длина этого горизонта для модели M3 составляет 90 дней см. Голубая линия соответствует усредненным значениям в пределах каждого скользящего окна размером в 9 наблюдений. Судя по большому разбросу полученных оценок MSE, качество модели M3 желает оставлять лучшего. Рассмотрим теперь, как описанную выше методологию выполнения перекрестной проверки можно применить для выбора оптимальной модели из нескольких альтернативных.
Предположим, что перед нами стоит задача выбрать оптимальную модель стоимости биткоина из построенных ранее моделей M4 , M5 и M Для описания качества этих моделей воспользуемся двумя метриками: MAPE и покрытие подразд. Для упрощения примера предположим также, что нас интересует качество предсказаний в целом для 90—дневного прогнозного горизонта то есть нам неинтересны отдельные даты этого горизонта.
Рассчитаем обе метрики качества для каждой из моделей—кандидатов:. Как видим, M12 лучше других моделей по обеим выбранным метрикам качества. Посмотрим, как выбранная нами оптимальная модель M12 сработает на этой проверочной выборке.
Однако следует подчеркнуть, что это всего лишь пример использования перекрестной проверки для сравнения качества предсказаний нескольких моделей: совершенно точно не стоит разрабатывать стратегию торговли биткоином на основе приведенных здесь результатов! Во всех примерах из предыдущих разделов этой главы предполагалось, что моделируемая переменная может расти во времени бесконечно. Классическим примером здесь будет численность популяции какого—либо биологического вида, которая ограничена имеющимися в среде обитания ресурсами.
Другой пример — количество пользователей какой—либо онлайн—услуги, которое ограничено доступом в Интернет. Важно отметить, что емкость системы может иметь ограничения и по нижнему порогу например, численность населения не может быть отрицательной. Одной из особенностей пакета prophet является возможность моделировать временные ряды для подобных систем. Рассмотрим, как это происходит. Есть два важных аспекта, которые не отражены в приведенном выше уравнении логистической функции Taylor and Letham Во—первых, емкость многих систем непостоянна.
Например, число людей, имеющих доступ в Интернет равно как и количество потенциальных пользователей того или иного онлайн—ресурса со временем возрастает. Например, выход новой версии продукта может значительно ускорить рост числа его потребителей.
В prophet для моделирования такого рода изменений вводится понятие точек излома тренда разд. Как задать этот параметр для подгонки модели? Часто у исследователя уже будет хорошее представление о емкости моделируемой системы например, компании обычно хорошо знают размер рынка, на котором они работают. Если же такого понимания нет, то придется потратить некоторое время на поиск дополнительной информации из сторонних источников например, прогнозы роста численности населения от Всемирного Банка, тренды в Google—запросах и т.
Для начала построим модель, в которой рост зависимой переменной ограничен по некоторому верхнему порогу. Для этого воспользуемся данными по стоимости биткоина за период с января г. Предположим, что несмотря на свой экспоненциальный характер роста стоимость биткоина в будущем не могла превысить Для введения этого верхнего порога в модель необходимо добавить новый столбец с обязательным именем cap в таблицу с обучающими данными:.
Как видим, несмотря на экспоненциальный рост в историческом периоде, предсказанные значения стоимости биткоина постепенно выходят на плато, что обусловлено введенным в модель ограничением на рост.
Многие естественные системы имеют ограничения емкости не только по верхнему, но и нижнему порогу подобно упомянутой выше численности населения. В prophet имеется возможность учесть это обстоятельство путем добавления еще одного столбца — floor — в таблицы с обучающими данными и данными для расчета прогноза верхний порог при этом также должен присутствовать в обеих таблицах. Для демонстрации этой возможности воспользуемся данными по стоимости биткоина в г.
В рассмотренных выше примерах предполагалось, что и верхний, и нижний пороги емкости системы постоянны. Анализ временных рядов с помощью R Аннотация Благодарности Дополнительные форматы книги 1 Введение 1.
Анализ временных рядов с помощью R. ГЛАВА 6 Пакет prophet Прогнозирование — это, пожалуй, самая распространенная задача, возникающая при работе с временными рядами. Его легко установить стандартным образом из хранилища CRAN на Windows—машинах предварительно нужно будет установить Rtools : install.
Если аргумент df не указан NULL , то произойдет только инициализация модельного объекта, а для непосредственного запуска подгонки модели необходимо будет воспользоваться функцией fit. Если вектор changepoints не указан, то такие переломные моменты будут оценены автоматически. Если аргумент changepoints задан, то аргумент n.
Если же changepoints не задан, то n. По умолчанию составляет 0. Принимает следующие возможные значения: "auto" автоматический режим, принят по умолчанию , TRUE , FALSE или количество членов ряда Фурье, с помощью которого аппроксимируется компонента годовой сезонности.
Возможные значения те же, что и у yearly. Принимает два возможных значения: "additive" аддитивный, задан по умолчанию и "multiplicative" мультипликативный.
Более высокие значение позволят иметь больше таких точек излома что одновременно увеличит риск переобучения модели. При "mcmc. Если же mcmc.